Per-Tenant Concurrency Caps: Protecting Well-Behaved Tenants from a Bursty Neighbor
Third post in a series on running vLLM on EKS. The first post covered the build. The second covered capacity. This one covers the next thing that breaks once more than one tenant shares a cluster: a bursty tenant ruining latency for everyone else.
The setup
Three tenants share one vLLM pool.
- Tenant A — steady, well-behaved. 2 requests per second.
- Tenant B — bursty attacker. Idle most of the time, then 30 rps for ~30 seconds.
- Tenant C — steady background. 1 request per second.
Every request across every tenant is the same size: 512 input tokens, 128 output tokens. Real production workloads have wide variance in both, and that variance is itself a fairness concern (a tenant with long completions extracts more GPU time per request than one with short completions). I'm deliberately holding it constant here. The point of this post is the burst-rate dynamic, and a uniform per-request cost makes the data easier to reason about — every observation is about request volume, not request cost.
The gateway is a small FastAPI app in front of vLLM Production Stack: every request carries a per-tenant API key, gets tagged with tenant_id, and is forwarded as a streaming SSE response. The gateway exposes Prometheus metrics with tenant_id as a label.
The question this post answers: when B bursts, how much do A and C get hurt — and what's the smallest, most defensible thing I can put in front of vLLM to make B's burst stop being A and C's problem?
See below for the result as a single Grafana screenshot. Three runs side-by-side: baseline (A and C only), caps-OFF (B bursts, no protection), and caps-ON asymmetric (B bursts, gateway sheds B's load). A's and C's p99 TTFT lines are flat in the first and third runs, and the middle one is a wall.
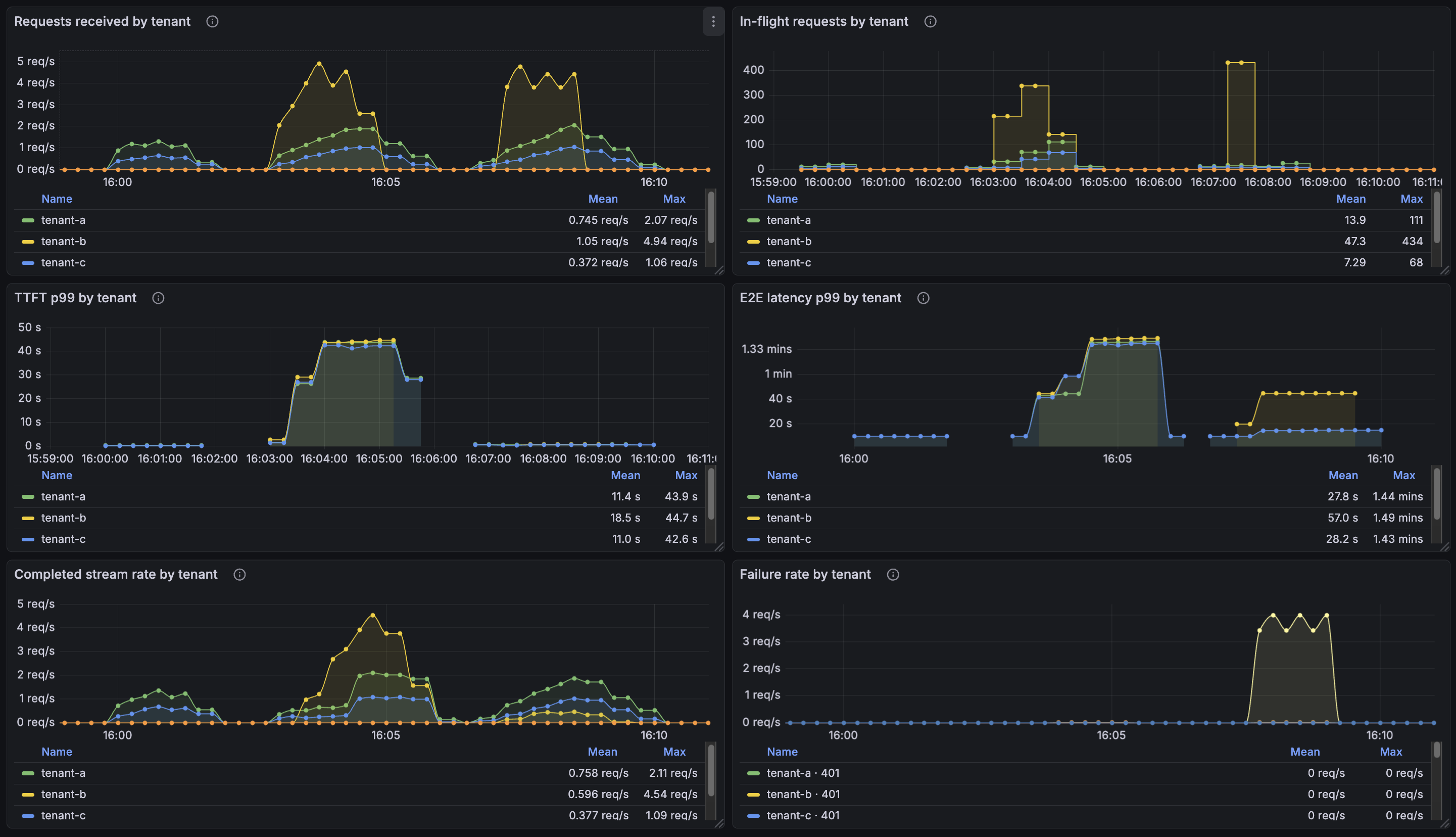
Run 1: baseline
Just A and C, no B. Sanity check that the gateway and vLLM aren't doing anything weird at low load.
| Tenant A (2 rps) | Tenant C (1 rps) | |
|---|---|---|
| Median TTFT | 195 ms | 187 ms |
| p99 TTFT | 263 ms | 230 ms |
| Median per-token decode | 61 ms | 61 ms |
| Failures | 0 / 120 | 0 / 60 |
This is what "healthy" looks like. ~200 ms first-token latency, ~60 ms per output token. We will compare everything else against this.
Run 2: B bursts, caps OFF
Same A and C. Now B opens up at 30 rps for 30 seconds and the gateway has nothing in front of vLLM.
| Tenant A | Tenant B | Tenant C | |
|---|---|---|---|
| Median TTFT | 1,280 ms | 5,514 ms | 6,137 ms |
| p99 TTFT | 33,200 ms | 34,277 ms | 32,444 ms |
| Median per-token decode | 131 ms | 267 ms | 134 ms |
| Peak concurrent in-flight | 126 | 450 | 73 |
| Failures | 0 / 240 | 0 / 450 | 0 / 120 |
No failures across the board. Service is heavily degraded but no requests were lost — every tenant's requests eventually completed. The failure mode here is latency, not availability.
Two things happened to A and C, and they're worth separating because they're caused by different mechanisms.
TTFT exploded. Tenant A — sending the same 2 rps as in the baseline — went from a 263 ms p99 first-token latency to 33.2 seconds. C went from 230 ms to 32.4 seconds.
With no caps in front, all of B's requests reach vLLM and sit in its waiting queue alongside A's and C's. A request from A that arrives during the burst is interleaved with hundreds of B's requests inside vLLM's scheduler.
Per-token decode also got 2× slower. This is the less obvious one: In the baseline, every output token took ~61 ms to generate. Under B's burst, A's tokens take 131 ms, C's take 134 ms, and B's take 267 ms. Everyone's decode got slower. Even tenants who aren't bursting.
This is vLLM's KV cache going into preemption. Under normal load, vLLM batches active requests together and decodes them in parallel — every request makes one token's worth of progress per step. When the running set gets too large to fit in KV cache, vLLM has to evict partially-completed requests, recompute their state when their turn comes back around, and the per-step decode time stretches because the batch is fighting cache misses on top of compute. Once vLLM is in preemption regime, every tenant pays — A and C's tokens are coming out of the same batched decode steps as B's, and that batched step is now slower per token because it's contending with swapping.
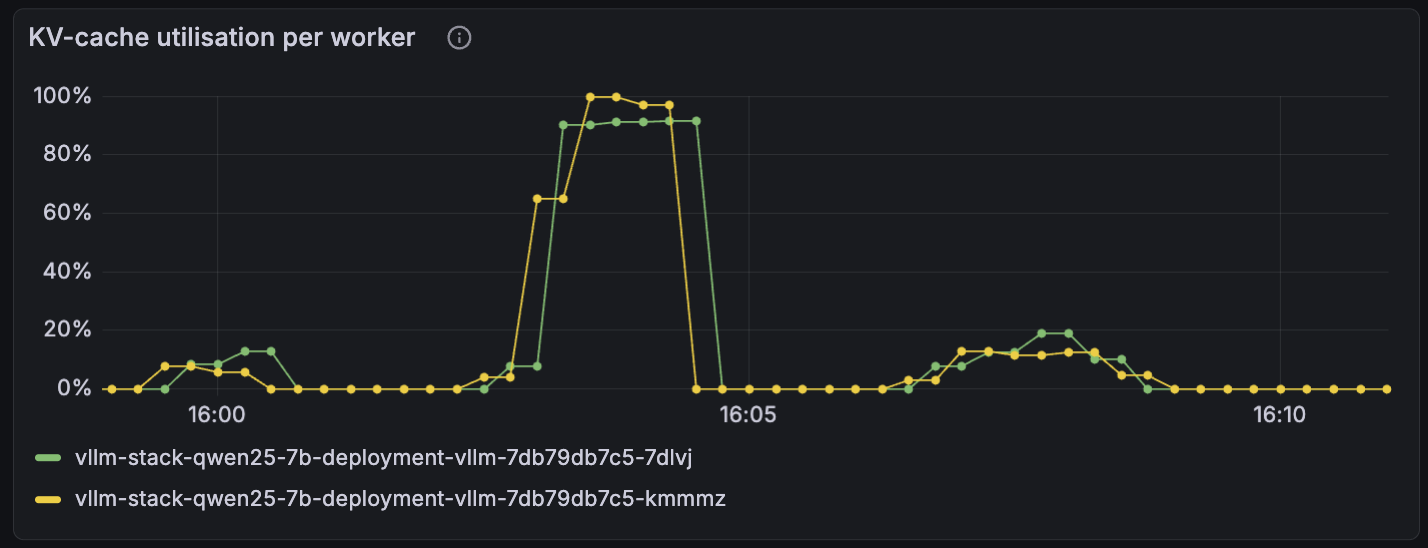
Both vLLM workers pin at ~100% KV-cache utilization for the duration of the caps-OFF burst (the tall plateau just before 16:05). The smaller bump after 16:07 is the same B burst with caps-ON asymmetric — total in-flight at vLLM stays bounded, KV-cache utilization peaks below 20%, and the workers never enter preemption.
So the failure mode isn't only "B blocks A in line." It's "B saturates vLLM, and a saturated vLLM serves all requests slowly."
How to limit access to inference?
The instinct, when "bursty tenant ruins latency for everyone else" comes up, is per-tenant rate limiting. A request-rate limit: tenant B gets 5 requests per second, anything past that gets rejected. This is the right answer for a CRUD API. It is not the right answer for inference.
The reason is that requests-per-second is the wrong unit. In a CRUD API, every request costs roughly the same. In an LLM, a 4,000-token completion costs roughly 40× as much GPU time as a 100-token completion. A request-rate limit can't tell those apart. A tenant doing 10 rps of 100-token completions is fine. A tenant doing 10 rps of 4,000-token completions saturates the GPU. Same rate, very different cost.
Three primitives, ranked for fit:
| Primitive | What it bounds | Inference fit |
|---|---|---|
| Rate limit on requests per second | request frequency | Wrong unit — ignores per-request cost variance. |
| Semaphore on in-flight requests | concurrent GPU commitment | Better — bounds work in progress. Blunt about per-request cost, but what's "in flight" is what hurts vLLM. |
| Rate limit on output tokens per second | GPU compute consumed | Correct — directly tracks the scarce resource. |
I picked the middle one: an asyncio.Semaphore per tenant, sized to the maximum number of concurrent in-flight requests that tenant is allowed to have at the gateway. A request acquires a slot when it arrives and releases the slot when its full SSE response is delivered. While B is holding all of its slots, B's additional requests block (or, in our case, time out and return 504 — more on that later).
One detail worth being explicit about: under this specific synthetic workload — fixed input length, fixed output length, near-zero variance in per-request cost — the in-flight semaphore is functionally equivalent to a rate limit on output tokens. Every slot held corresponds to the same amount of GPU work. Picture each slot as a fixed-size budget consumed in one chunk per request; same admission shape, same throughput, same fairness. The output-token rate limit only earns its complexity when output lengths actually vary across tenants — which they will in real production, but don't here.
The cap-sizing math
A request holds its semaphore slot for the entire response lifecycle — from arrival through the final SSE chunk delivered back to the client — not just until vLLM emits the first token. The cap has to be sized against that whole interval:
cap = arrival_rate × E2E_response_duration × headroom
= arrival_rate × (TTFT + output_tokens × per_token_decode_latency) × headroom
For A's workload (128-token outputs, ~75 ms inter-token latency at baseline) the full response takes about 10 seconds. TTFT is ~200 ms — 50× shorter than E2E.
Another way to think about it: A and C are paid users; B is on the free tier. The shedder's job is to protect paid-user SLAs when the free tier misbehaves. The caps I picked are:
cap_A = 64(paid)cap_C = 64(paid)cap_B = 8(free)
A's natural in-flight is 2 × 10 = 20; cap=64 gives ~3× headroom for E2E to stretch under load. C's natural is 1 × 10 = 10; same cap, more headroom. B's cap is sized to its sustained-rate budget, not its burst rate — when B opens up at 30 rps, the gateway holds the line at 8 concurrent and sheds the rest. The shedder takes the cost out on B and protects A and C.
The headroom factor matters because under burst the cap-sizing problem compounds: vLLM's per-request E2E latency grows with queue depth. A tenant whose natural in-flight fits comfortably under its cap at baseline can exceed it during burst as E2E stretches under the load.
Run 3: same burst, asymmetric caps on
Same B burst as run 2. Same A and C traffic. Caps are now (64, 8, 64).
| Tenant A | Tenant B | Tenant C | |
|---|---|---|---|
| Median TTFT | 304 ms | 16,900 ms | 207 ms |
| p99 TTFT | 603 ms | 30,536 ms | 472 ms |
| Median per-token decode | 68 ms | 67 ms | 68 ms |
| Peak concurrent in-flight | 30 | 40 | 18 |
| Failures | 1 / 240 | 404 / 450 | 0 / 120 |
A and C are back to baseline shape. p99 TTFT for A went from 33.2 s to 603 ms — a 55× improvement. C went from 32.4 s to 472 ms. Per-token decode is back to ~68 ms across the board, slightly above the no-burst 61 ms but nowhere near the 131-134 ms in the caps-OFF run. vLLM is no longer in preemption.
B has 404 failed requests out of 450 — those are the requests the cap is shedding. B is the tenant whose behavior is creating the problem, and the gateway is forcing the cost back onto B instead of letting it spread across A and C. The 46 of B's requests that did make it through were served at the same per-token speed everyone else was getting. B is throttled, not degraded.
The total in-flight at vLLM peaks at 30 + 40 + 18 = 88 requests across all tenants — an order of magnitude under the 450 peak in the caps-OFF run. That's the second-order win: the cap is protecting vLLM — its KV cache, its batch scheduler — and through that protection, every tenant gets clean batched decode. But this doesn't guarantee optimal GPU utilization (see last section).
Why 504 instead of 429
504 (block at gateway, time out) over 429 (reject immediately). When B exceeds its cap, the rejected requests sit at the semaphore's acquire() call until they hit the 30-second timeout, then return 504. The alternative is to check the semaphore non-blockingly and return 429 immediately. I chose 504 for the demo because it makes back-pressure visible — gateway_inflight_requests swells, the queue is observable, the dashboard tells the story.
For production, 429 is the correct answer. Rejected immediately means no resources held, clients can retry/backoff faster, no idle TCP connections sitting in the kernel. Real serving stacks (Modal, Baseten, Fireworks) generally use 429. v2 production version: 429 with optionally a small bounded queue for jitter absorption.
A few things that broke while building this
Most of the engineering time on this post was not in the cap logic itself — that's about 30 lines of FastAPI middleware. It was in the metrics needed to convince myself the cap was actually doing what I thought it was doing.
vLLM truncates streams under heavy load. Under unbounded caps-OFF burst, vLLM occasionally returns a 200 OK header, streams a few SSE chunks, and then closes the connection before sending the terminal [DONE] chunk. The bench client sees aiohttp ClientPayloadError: Response payload is not completed. The gateway proxy sees a clean 200 response that just happened to end early. Naive 200/non-200 status accounting overstated SLO success — the gateway was counting truncated requests as successful. The fix was a gateway_stream_completed_total{tenant_id, completed=true|false} counter, incremented only when the response iterator finishes via StopAsyncIteration rather than via exception. For streaming APIs, "what was the response status" and "did the user receive a complete response" are different questions, and I had been conflating them.
Sparse-counter metrics don't render with default rate() windows. The 504 (cap-rejected) series only exists during the burst — a few tens of seconds total. With a 30 s scrape interval and a rate(metric[2m]) window, the rate evaluator often had too few samples in-window and rendered as flatline-zero, even though the gateway counter clearly showed values in the hundreds. The fix is to pre-create every expected (tenant_id, route, status) series at gateway startup so that rate() has a baseline of zero to subtract from, instead of materializing the series mid-window.
Gateway memory is dominated by per-request httpx connections. Under caps-OFF burst with hundreds of concurrent in-flight requests, the gateway pod was OOMKilled at a 1 GiB memory limit. Each request was holding an httpx connection, request body buffer, and SSE response buffer — call it ~250 KB each, times thousands of concurrent requests, and you're at a gigabyte. In a streaming gateway, "open connections" is the dominant memory cost, not the Python process. The right fix is sharing one AsyncClient across requests (currently the code creates one per request). Bumping to 2 GiB was the duct tape.
What this design doesn't do
Static per-tenant caps protect isolation but they don't help achieve max utilization. When A is idle, A's 64 reserved slots sit unused. The caps don't redistribute spare capacity to whichever tenant happens to be busy — they just hold the line. In the run-3 numbers above, total in-flight at vLLM peaked at 88. The cluster is sized for substantially more than that, but with caps in place we leave that capacity on the floor whenever everyone happens to be polite at the same moment.
The cap values also depend on workload-specific latency assumptions that change as the system loads up. Under burst, E2E latency stretches, and the cap-sizing math rate × E2E × headroom produces a different answer than it did at baseline. In practice this means caps need either generous headroom (which costs utilization in the steady state) or manual retuning (which is operational work that doesn't scale across tenants). Neither is great.
The next thing I'd build is the layer that fixes both of those. A weighted-fair-queueing scheduler over a global in-flight budget, where the budget itself is continuously tuned by an AIMD controller against an observed-latency signal. When only A is active, A gets the full budget — high utilization. When everyone is active, the budget is shared by weight, and overflow returns 429 (or 504, depending on the same tradeoff as above). The static cap becomes a hard ceiling underneath the adaptive layer.
Repo
Terraform, Helm manifests, gateway code, the bench scenarios, and the Grafana dashboard JSON used for the screenshot above are in the public repo. The three runs in this post are reproducible end-to-end against a fresh cluster.